🧪테스트주도개발(TDD) 하기 | Apache Jmeter를 이용한 부하테스트
부하테스트가 필요할때마다 꾸준히 쓰고있는 툴인 Apache Jmeter
자주 사용하다보니 시리즈물처럼 블로그에 포스팅도 자주 했었던 주제였는데,
테스트 주도 개발에 핵심으로 쓰이는 툴 같아서.. 이번에 부하테스트를 또한번 진행하게 되면서
테스트주도개발과 엮어서 설명해보려고 합니다.

[JMeter] kafka 테스트 툴 | 성능 및 부하테스트
사용목적 : JMeter를 이용하여 서버 연동을 확인하고, Kafka Produce를 진행한다. 1. JMeter 설치 https://jmeter.apache.org/download_jmeter.cgiapache-jmeter5.5.zip 다운로드 2. plug-in 설치 플러그인 사이트 : https://j
esclife.tistory.com
Apache Jmeter 사용방법 | Kafka Producer/Consumer 테스터, 카프카를 다량으로 발송해서 부하테스트 하기
✳️ Apache Jmeter 소개&설치📌 설치Binaires - zip 파일을 다운받아주세요. 경로는 상관없어요. 저는 바탕화면에 받았습니다.https://jmeter.apache.org/download_jmeter.cgi Apache JMeter - Download Apache JMeterDownload Ap
esclife.tistory.com
[Jmeter] apache jmeter에서 host에 접근하지 못할때 | dev-kafka 오류 | di-kafkameter 오류 | jmeter timeout exception
jmeter 활용중 log에 "dev-kafka" 어쩌구 하면서 host 주소로 요청실패하는 오류가 계속 발생했습니다.Timeout이 계속 발생하고, request 자체에 실패했는데요. 로컬 PC에서 jmeter를 실행할 때 이러한 오류를
esclife.tistory.com
[Jmeter] 요청 전송주기 설정 라이브러리 - Timer 설정
📌 Thread group - 1시간 동안 테스트진행 Action to be taken after a Sampler error : 테스트 중 샘플러(Sampler)가 오류를 반환했을 때 수행할 동작을 설정 Continue : (계속진행) 오류가 발생해도
esclife.tistory.com
[BlazeMeter] jmeter의 .jmx 테스트시나리오를 동영상녹화로 자동생성하는 확장프로그램
회사에서 다양한 테스트에 jmeter를 활용하게 되면서우연히 찾게된 크롬의 확장프로그램BlazeMeter jmeter에서 실행되는 테스트시나리오를동영상녹화로 자동 생성해주는 프로그램입니다. https://chrome
esclife.tistory.com
FCM(Firebase Cloud Messaging) 서비스를 개발하면서.. (1)
FCM은 Firebase Cloud Messaging의 약자입니다.Firebase(구글의 모바일/웹 앱 개발 플랫폼) 위에서 돌아가는 클라우드 기반 메시지 푸시 서비스를 말합니다. 회사에서 FCM을 이용한 스마트폰 푸시 알림 서비
esclife.tistory.com
(이번 포스팅 다 읽어보시구, 궁금하시면 위에 포스팅 하나씩 들어가보시면 jmeter에 대한 사용방법을 쉽게 익히실 수 있을꺼에요)
🚀 JMeter를 이용한 TPS 기반 성능 측정
이번에 진행해 볼 테스트주도개발의 목표는 '성능 측정' 입니다.
사실 테스트주도개발을 모~두 마치고 마지막에 성능을 측정하는 시점에 진행하는게 부하테스트이지만...
TDD 사이클을 통해 기능적으로 완성된 코드가, 최종적으로 실제 사용자 트래픽 환경에서도 초당 처리량(TPS)과 응답 시간 등 핵심적인 비기능적 요구사항을 충족하는지 최종적으로 검증하는 과정으로서,
개발의 최종 결과물이 사용 준비가 되었는지 평가하고, 혹시라도 만족스럽지 못한 성능이 관찰될 경우 병목 지점을 찾아 개선하는 데 매우 중요한 역할을 하기때문에. 테스트주도개발 태그에서 소개하게 되었어요.
부하 테스트는 TDD의 직접적인 부분은 아니지만, TDD로 완성된 개발 결과물의 품질과 적합성을 최종적으로 보증하는 중요한 단계입니다.
1. TPS (Transaction Per Second)의 의미
- TPS는 Transaction Per Second의 약자로, 초당 처리되는 트랜잭션(요청) 수를 의미합니다.
- 성능 테스트에서 TPS는, 시스템이 1초 동안 정상적으로 처리할 수 있는 최대 부하량을 나타내는 핵심 지표입니다.
2. 적정 테스트 TPS 기준
- 보통 몇 TPS로 테스트해야 하는가?에 대한 정답은 없으며, 테스트 목적과 시스템 상황에 따라 달라집니다.
- 현행 서비스 Peak 부하 (Baseline): 현재 서비스의 최대 피크 시간대 TPS를 확인하고, 그보다 1.5배 ~ 2배 정도의 부하로 테스트하여 시스템의 여유 용량을 확인하는 것이 일반적입니다. (현재 시스템이 안정적으로 처리할 수 있는 부하의 기준선)
- SLA (Service Level Agreement): 서비스 품질 보증 기준이 있다면 해당 기준을 만족하는지 확인합니다.
- 목표 성능 (Future Goal): 향후 예상되는 최대 부하 목표(예: 1년 후 예상 피크 부하)를 설정하고, 이 부하를 견디는지 확인합니다.
결론 : 정확한 측정을 위해서는 실제 서비스에서 발생하는 시간당/분당 최대 요청 건수를 기반으로 TPS를 설정하는 것이 가장 정확합니다. 제가 테스트할 시스템은 사내에서 200 ~ 1000 TPS를 시험하는 것으로 기준선이 정해져 있었어서 동일하게 200에서 점진적으로 늘려가며 1000TPS까지 올려가며 목표 성능을 측정할 예정입니다.
3. 그럼에도..!! TPS 적정 수준
기존에 운영되고 있던 시스템이 아닌 신규 시스템이라던가, 기준이되는 TPS 설정을 세울만한 정보가 부족할경우..
그럼에도 ! TPS 기준을 세워야한다면 어느정도의 값으로 설정하여 테스트해야 할까요?
A. 설정 적합성 (400 TPS) 판단
- FCM(App Push) 서비스의 특성: 푸시 서비스는 보통 대규모 메시지를 짧은 시간에 처리해야 하므로, 높은 TPS가 요구됩니다.
- 400 TPS (초당 400건): 이는 분당 24,000건, 시간당 약 144만 건의 요청입니다. 일반적인 앱 서비스에서 하루에 요청받는 푸시가 3천 건이 최대라고 가정했을때(이러한 가정은 유저가 3천명이고 하루에 1번만 공지알림 푸시가 나간다.. 라는 기준에서 가능한 얘기겠죠?), 400 TPS는 매우 높은 부하이며, 시스템이 이 부하를 견딜 수 있는지 테스트하는 것은 최대 성능(Peak Performance)을 측정하는 좋은 방법입니다.
🔧Jmeter 설정
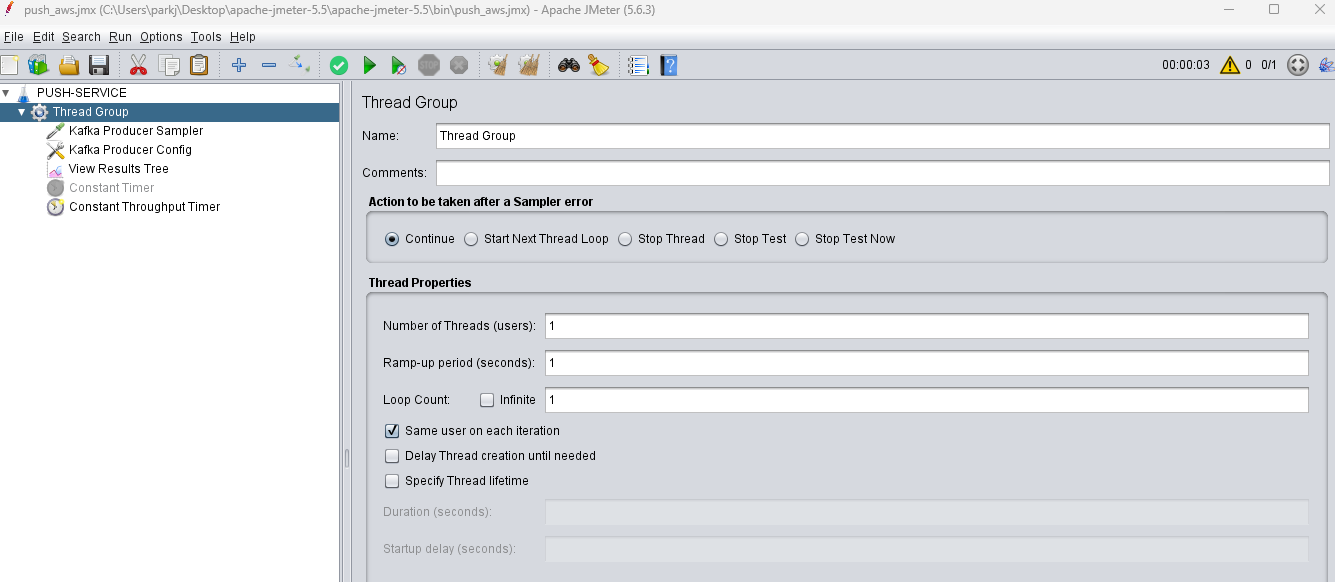
1. Thread Group
테스트 목적이 정확히 특정 TPS를 유지하는 것이라면,
위와 같이 1개의 Thread와 Infinite Loop를 설정하는 방식이 Constant Throughput Timer와 함께 사용할 때 가장 적합합니다.

| 설정 항목 | 제안 값 | 적합성 및 이유 |
| Number of Threads (users) | 1 | Constant Throughput Timer 설정 시, Calculate Throughput based on: This thread only 옵션과 함께 사용하면 가장 정확하게 목표 TPS를 제어할 수 있습니다. |
| Ramp-up period (seconds) | 1 | 스레드가 1개이므로 중요하지 않지만, 1로 두면 즉시 실행됩니다. |
| Loop Count | Infinite | 장시간 동안 일정한 부하를 유지하며 성능을 측정하는 데 적합합니다. |
| Same user on each iteration | Checking | 테스트 토큰이 1개이므로 체크 여부는 영향이 적지만, 체크하여 매번 동일한 설정으로 요청하도록 합니다. |
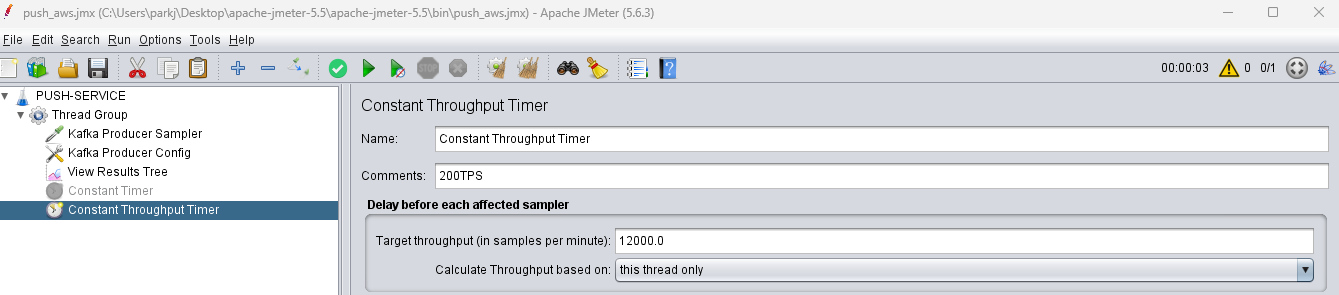
2. Constant Throughput Timer
특정 TPS를 설정해서 다수의 요청을 보내고 싶을땐, 보통 자주쓰이는 Constant Timer 대신에
Constant Throughput Timer를 사용해야 합니다.
(이미지에 보시면 기존의 Constant Timer 설정파일은 Disable로 우클릭설정 해놓았고,
Constant Throughput Timer를 Enable로 활성화 시켜놓았어요)

| 타이머 | 목적 | 적합성 |
| Constant Timer | 각 요청 간의 지연 시간을 설정하여, 스레드 당 요청 속도를 간접적으로 조절합니다. | 특정 TPS 설정에는 부적합합니다. 시스템 응답 시간에 따라 전체 TPS가 변동될 수 있습니다. 단순, 요청건 당 Thread.sleep을 설정하는 Timer라고 보면 되겠습니다. |
| Constant Throughput Timer | 시스템 전체의 목표 TPS를 설정하여, JMeter가 스레드 수와 응답 시간을 고려해 자동으로 요청 간 지연 시간을 조절합니다. | 특정 TPS를 유지하는 성능 측정에 가장 적합합니다. |
🧑💻TPS 기반 성능 측정
권장 테스트 순서
- Baseline Test: 기존 최대 TPS (매우 낮을 경우)를 기준으로 시작합니다.
- Step-up Test: 100 TPS ➡️200 TPS ➡️ 300 TPS ➡️ 400 TPS...와 같이 단계적으로 부하를 증가시키면서, 응답 시간이 급격히 느려지거나 오류율이 발생하는 지점(Bottleneck)을 찾아내야 합니다.
200 TPS로 시작하여 안정적으로 유지되는지 확인하고, 가능하다면 500, 600 TPS까지 올려보며 시스템이 버틸 수 있는 최대 성능을 측정해 보세요.

🚧 병목 현상 (Bottleneck) 발생 기준
성능 테스트에서 병목 현상은 시스템이 더 이상 정상적인 성능을 유지하지 못하고 성능 저하가 발생하는 지점을 의미합니다. 단계적 부하 증가(Step-up Test) 시 병목 현상을 판단하는 객관적인 기준은 다음과 같습니다.
1. 응답 시간 (Response Time) 기준 ⏱️
응답 시간이 급격히 증가하거나, 서비스 수준 협약(SLA)에서 정한 기준을 초과할 때 병목 현상이 발생했다고 판단합니다.
- SLA 위반: 서비스가 응답해야 하는 최대 허용 시간 (예: 95%의 요청이 500ms 이내)을 초과할 경우.
- 급격한 증가: 부하를 증가시킨 시점에서 평균 응답 시간이 이전 단계 대비 비정상적으로, 급격하게 증가할 경우. (일반적으로 20% 이상 증가 시 경고 신호)
2. 오류율 (Error Rate) 기준 ❌
시스템의 오류 발생률이 허용 수준을 넘어설 때 병목 현상으로 간주합니다.
- 오류율 상승: 오류율 (Error Rate)이 0%가 아닌 1% 또는 2% 이상으로 증가하기 시작할 경우. 이는 시스템 내부 자원(DB 연결, Thread Pool 등)이 고갈되거나 타임아웃이 발생하기 시작했다는 강력한 신호입니다.
- 부하 실패: 서버에서 **5xx (Server Error)**나 4xx (Client Error, 특히 타임아웃) 응답이 빈번하게 발생하기 시작하는 시점입니다.
3. 서버 자원 활용률 (Resource Utilization) 기준 📉
시스템이 부하를 처리하기 위해 과도하게 자원을 사용하기 시작하거나 고갈될 때 병목 현상의 징후를 보입니다.
| 자원 | 병목 징후 |
| CPU | 활용률이 80%~90% 이상으로 지속적으로 유지될 때. |
| Memory | 힙 메모리(Heap Memory) 사용량이 증가하고, GC(Garbage Collection) 횟수나 시간이 급격히 증가할 때. |
| Disk/I/O | 디스크 Read/Write 대기 시간이 길어지거나 대역폭이 한계에 도달할 때. |
| Network | 네트워크 인터페이스의 사용률이 80% 이상으로 포화되기 시작할 때. |
이러한 징후가 발생했다면, 해결하기 위한 주요 전략은 크게 두 가지로 나뉩니다.
- 성능 튜닝 (Performance Tuning): 현재 자원을 더 효율적으로 사용하도록 시스템 내부를 최적화합니다.
- 서버 스케일링 (Server Scaling): 시스템에 더 많은 자원을 투입하거나 서버 대수를 늘립니다.
일반적으로는 성능 튜닝을 먼저 시도하여 현재의 자원을 최대한 활용하도록 만든 후, 자원의 물리적 한계에 도달했을 때 서버 스케일링을 고려하는 것이 비용 효율적입니다.
💡 외부서비스 테스트 시 특히 중요한 기준
외부 서버로 요청을 보내고 응답을 받아야 하므로, 특히 다음과 같은 지표를 주의 깊게 봐야 합니다.
- Thread Pool 포화: FCM 요청을 처리하는 백엔드 서버의 Thread Pool이 고갈되어 더 이상 새로운 요청을 처리하지 못하고 대기열이 길어지는 시점. (응답 시간 급증의 주 원인)
- 외부 API (FCM) 의존성: FCM 서버의 응답 지연으로 인해 테스트 시스템 내에서 타임아웃 오류가 발생하기 시작하는 시점.
요약: 테스트를 진행하며 응답 시간, 오류율, 그리고 CPU/메모리 활용률을 동시에 모니터링했을 때, 셋 중 하나라도 허용치를 넘어서기 시작하는 TPS가 바로 현재 시스템의 병목 현상 시작 지점이며, 이는 곧 최대 허용 TPS로 간주할 수 있습니다.
💻 성능 테스트 결과 모니터링 방법
jmeter로 다수 요청을 발송한다고 했을때 결과 모니터링은 어떻게 할 수 있는지 알려드릴께요.
성능 테스트의 성공적인 분석을 위해서는 부하 생성기(JMeter)와 피테스트 서버(SUT) 간의 상태를 동시에 관찰해야 합니다.
1. JMeter 클라이언트 측 모니터링 (결과 확인)
JMeter가 요청을 보내고 받는 결과를 실시간으로 확인하는 방법입니다.
| 모니터링 방법 | 설명 | 장점 |
| 결과 요약 (Summary Report) | 테스트가 끝난 후 평균 응답 시간 (Latency), 처리량 (Throughput, TPS), 오류율 (Error Rate) 등을 집계하여 보여줍니다. 가장 기본적이고 중요한 지표입니다. | 테스트 결과를 한눈에 파악 가능 |
| View Results Tree | 개별 요청의 성공/실패 여부와 상세 응답 메시지를 실시간으로 확인합니다. | 오류 발생 시 원인 분석에 필수적 |
| Backend Listener (Grafana 연동) | JMeter 결과를 InfluxDB 같은 시계열 데이터베이스에 전송하고, Grafana 같은 UI 툴로 실시간 그래프를 구성하여 확인합니다. | 시각적이고 직관적이며, 장시간 테스트에 유용합니다. |
2. SUT (서버) 측 자원 모니터링 (병목 현상 진단)
서비스가 올라가 있는 서버의 자원 활용률이 병목 현상의 징후(80% 이상)를 보이는지 확인하는 방법입니다.
A. 리눅스 명령어 기반 모니터링 (저부하, 상세 기록)
서비스가 올라가있는 서버내에서 sar 명령어를 사용하여 서버에 부하를 주지 않으면서 장시간 동안 자원 사용량을 기록하는 것이 가장 효과적입니다.
| 명령어 | 측정 항목 | 설명 |
| sar -u 1 N | CPU | 1초 간격으로 N회 동안 CPU 사용률(%user, %system, %iowait 등)을 측정합니다. |
| sar -r 1 N | Memory | 1초 간격으로 N회 동안 메모리 사용량 (kBmemused, kBfree 등)을 측정합니다. |
| sar -n DEV 1 N | Network | 네트워크 트래픽(패킷/초, kB/초)을 측정하여 네트워크 병목을 진단합니다. |
실제 활용 스크립트 예시 (60초 테스트):
# 1초 간격으로 60회 (총 60초) CPU 사용량 측정
sar -u 1 60
B. UI/UX 기반 모니터링 (Grafana, VisualVM)
- Grafana: Prometheus, Telegraf 등과 연동하여 서버 자원(CPU, MEM, Disk) 상태를 실시간으로 대시보드에서 확인할 수 있습니다. 테스트 진행 상황과 서버 부하를 동시에 파악하는 데 최적입니다. 서비스 설정파일과 그라파나 서버간의 설정을 맞추어서 웹으로 접속해 통계화면을 볼 수 있어요.

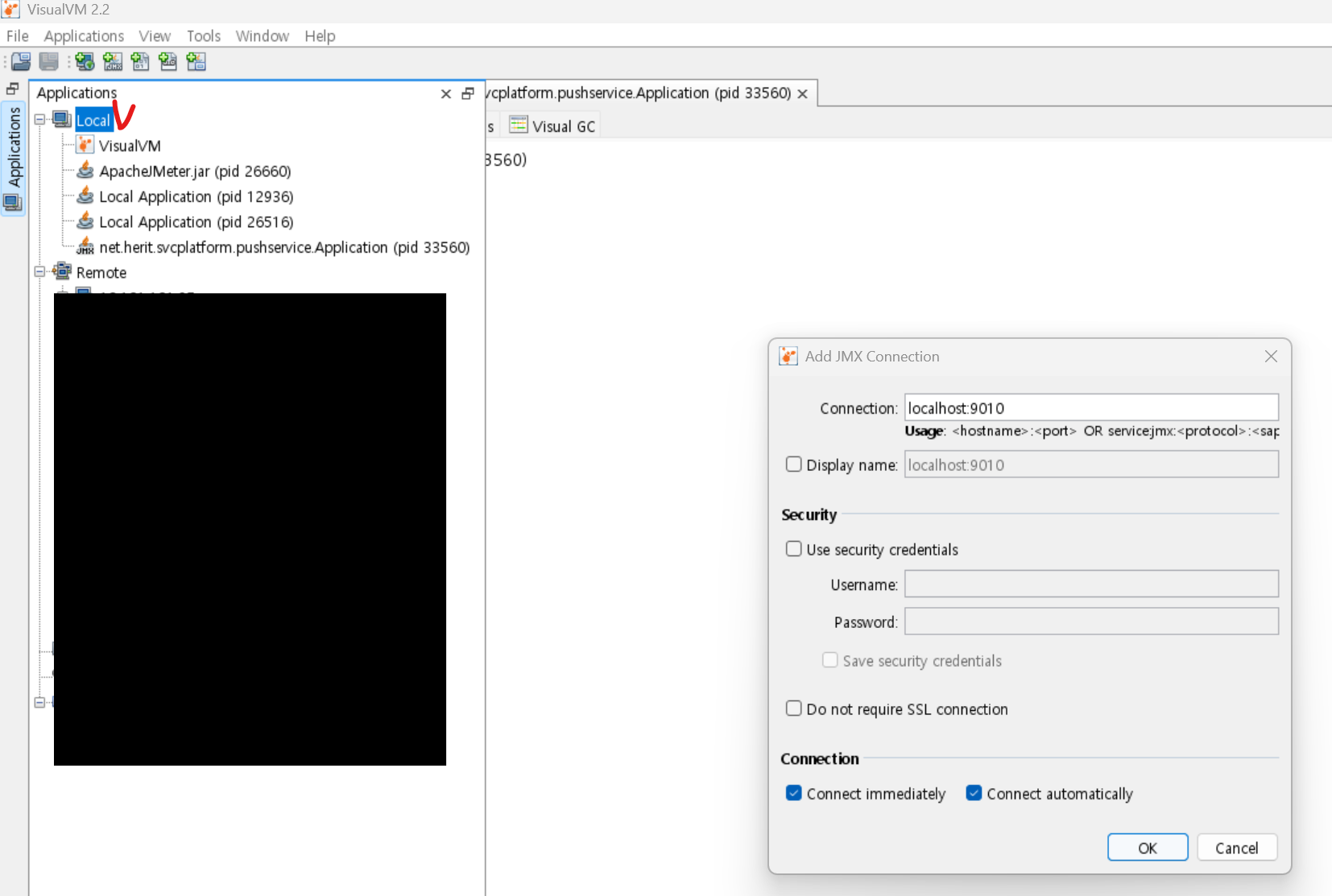
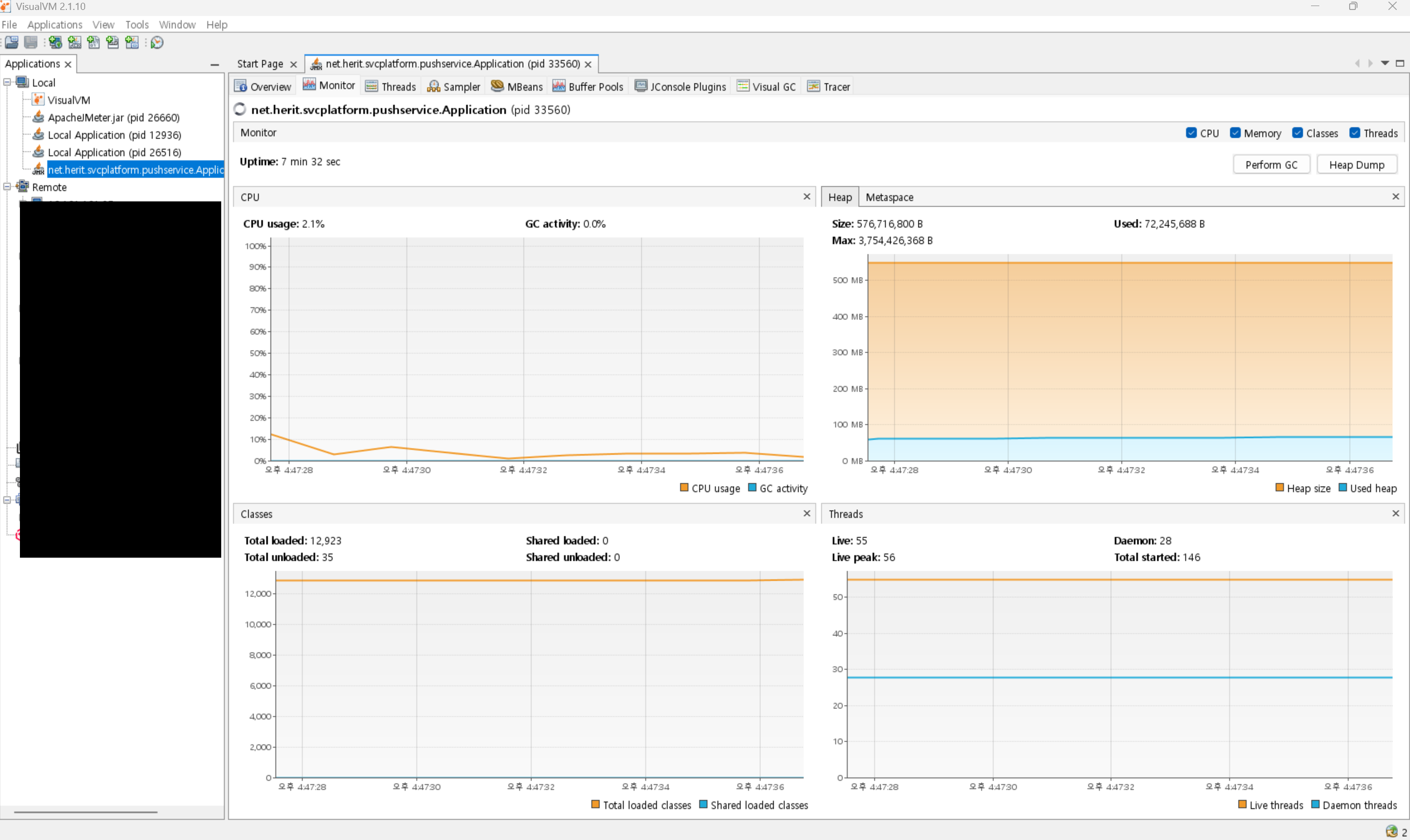
- VisualVM: Java 기반 애플리케이션의 JVM 내부 상태 (Heap 메모리 사용량, GC 발생 빈도, 스레드 상태)를 실시간으로 모니터링하는 데 매우 유용합니다. 메모리 병목(GC) 징후를 진단할 때 필수적입니다. 이 툴은 보통 로컬에서 부하테스트를 진행할때 사용하고 있는데요.(물론 외부서버에올린 서비스도 모니터링 가능). 설정이조금 필요합니다. 로컬 기준으로 서비스 프로젝트에서 RUN/DEBUG Configuration 설정에 add VM options을 추가해주시고, 추가한 포트로 visualVM에서 Add JDX를 해서 모니터링이 가능해요.
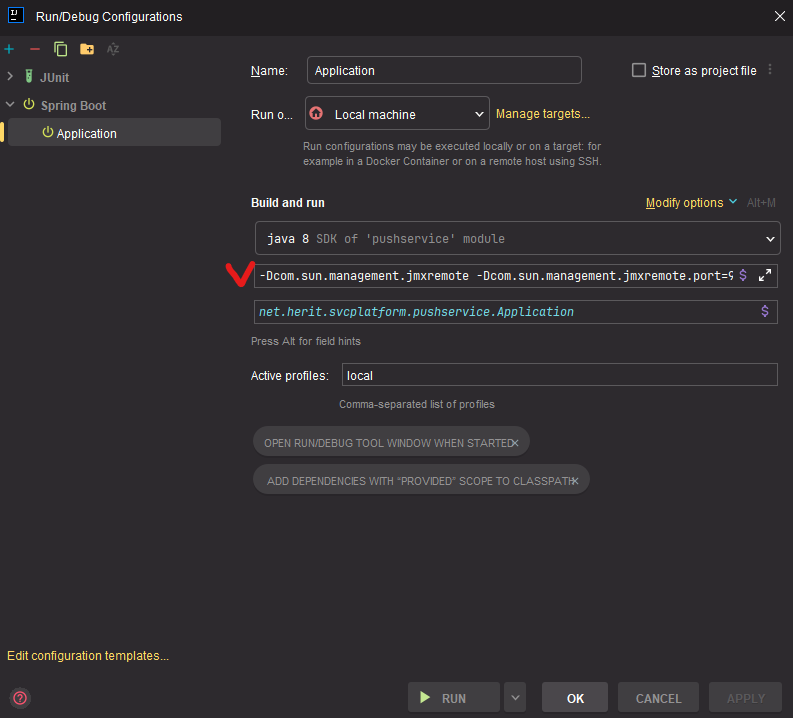
-Dcom.sun.management.jmxremote
-Dcom.sun.management.jmxremote.port=9010
-Dcom.sun.management.jmxremote.authenticate=false
-Dcom.sun.management.jmxremote.ssl=false
-Djava.rmi.server.hostname=127.0.0.1
설정하고 서비스를 기동한후에, visual vm에 가서 VM옵션으로 설정한 포트를 적어주면 연동해서 볼 수 있음.
visualVM의 장점은 OOM이 발생하는 시점에 heapdump를 버튼으로 뜰 수 있다는 점..!!!!!
이거 매우 유용해요... 모니터링을 UI로 보다가 그래프가 상승하면서 서비스가 멈추는 시점에...!
heapdump 버튼으로 간단하게 떠서 원인분석하면되니까.
저는 로컬에서 먼저 테스트돌릴때 꼭 visualVM툴을 사용한답니다.
3. 애플리케이션 로그 기반 모니터링
로그 레벨을 성능 시험 버전으로 높여 설정하신 것처럼, 요청 처리 시 발생하는 상세 로그를 분석하여 문제점을 찾아냅니다.
- 응답 코드 분석: 로그에서 |200|0| 외의 실패 응답 코드(|500|, |404| 등) 발생 빈도를 분석합니다. (grep -v 활용)
- 처리 시간 추적: 요청의 시작 및 종료 시간을 로그에 기록하여, 서버 내부의 어떤 단계(DB 호출, 외부 API 호출 등)에서 지연이 발생했는지 정밀하게 추적합니다.
이 세 가지 방법을 조합하여 모니터링하면, "몇 TPS까지 안정적인가" 뿐만 아니라 어디에서(CPU, MEM, Network, DB) 병목이 발생했는가까지 정확하게 진단할 수 있습니다.